


The Skeptic AI Enthusiast #25
The current tech landscape seen critically by an AI veteran


25 issues already of the Skeptic AI Enthusiast! Is that an accomplishment?
In a way, it sounds a bit like birthdays, where the “accomplishment” is just to allow for the passage of time. But I feel it differently: the newsletter is a form of interaction, and each issue is a bit different from all the others.
And I feel grateful that you stay around.
Thanks for reading!
My take on the news
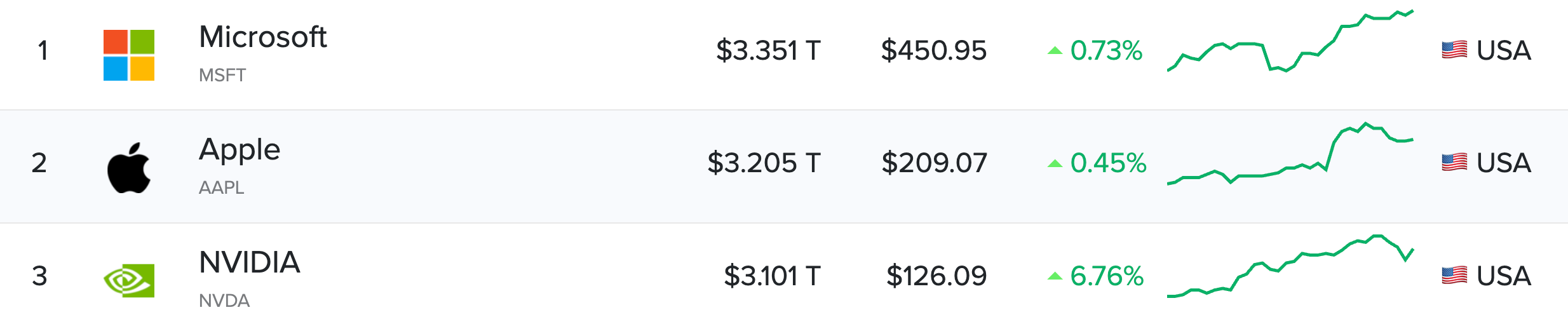
Apple briefly takes the top spot in most valuable companies:

Wait! Nvidia is now at the top! Wait again; Microsoft is now the top one!
Yes, as the “market capitalization” value depends on the stock market, it’s subject to volatility and sensitive to faint market trends. For instance, Apple rose to the top after its announcement of “Apple Intelligence,” as analysts (rightly) saw the implications of having 1,500 million active Apple devices using some form of AI. Then Microsoft went back to the top. I think these three will have turns at the top spot…Anthropic's newest model, Claude 3.5 Sonnet, has impressive capabilities:
One more LLM takes the lead in the race for the top AI conversational system, and this time, it’s not coming from Google or OpenAI, but Anthropic instead.
See the following comparison chart:
We can see that Claude 3.5 is ahead in some important categories, like coding and grade school math. To me, this shows that most aspects of LLM development are common knowledge among the biggest companies, so there isn’t a single overall leader.
New CarPlay will be wireless –and let car makers make the design:
Many of us solve the issue of having to plug our iPhones into the car by buying one of those inexpensive Chinese dongles (I use the AutoSky one).
But CarPlay will change a lot in future iterations. For one thing, Apple will release control (something incredibly difficult for them) to car makers in some parts of the interface. A much deeper integration is expected between Apple and car makers. Oh, and it will be wireless by default!

This week’s quote
I've tried this "artificial intelligence" plant identification app multiple times on the same tree and got a different answer each time. They must be using random forest!
– Michael Hoffman
A tongue-in-cheek take on the limitations of current image-interpretation AI systems.
This week’s resource
I found a very technical resource that some of you may find useful. It’s about where and how to apply either Retrieval Augmented Generation (RAG) or additional training (fine tuning). These two are different alternatives for tailoring a general LLM to a specific need.
So here it goes:
RAG vs. Fine-tuning for Multi-Tenant AI SaaS Applications
What is…?
Giant Chips!
We thought microprocessors were giant chips, but they are not, at least not compared to a new generation of computational chips intended to achieve supercomputing power at a much smaller scale.
Cerebras is a California-based company that produces large, extremely large chips instead of connecting together many GPUs, as it is done today. We are talking about putting 4 trillion transistors into one single wafer. That’s insane! But it makes sense if you consider that giant chips could double the computing power for the same electric consumption. And you know that electric consumption has become a big issue when it comes to environmental consequences of Artificial Intelligence.
This level of computing power is needed for specialized tasks such as protein folding, molecular dynamics simulations, weather forecasts, and, yes, LLM training!
Blog piece highlights
Today, I uploaded my blog post, “I Invented a Way to Speak to AI That Doesn't Make You Look Silly.” You guessed it right, it’s about “Silent Voice,” the technology I recently patented. Its highlights are the following:
Though voice dictation is a great way of giving textual information to AI, there are many situations where you don’t want to talk to a phone in front of people. For starters, you don’t want to look silly. Or you don’t want people to overhear sensitive information.
“Silent Voice” solves these issues by allowing you to speak “silently” to your phone.
Silent Voice consists of an ultrasound generator and speaker, which throw short ultrasound pulses to your mouth, and a mic that picks up the echo going back.
The echo gets distorted by the “vocal tract” (the tongue and other parts), so a classifier tries to identify which “phoneme” is associated with a particular pattern of distortion.
Phoneme classification is a critical task in Silent Voice. It’s done using a standard Machine Learning process.
We can sum up Silent Voice with the “equation:”
Silent Voice = Ultrasound echo + Machine LearningAs in every Machine Learning standard process, there are stages such as raw data collection, feature extraction, dataset partition, training a classifier, and classification quality assessment.
Other Silent Voice use cases include extremely noisy environments (think you get a call during a live concert) and people who lost the capacity to speak due to an injury or sickness.
Silent Voice is part of “Silent Speech Interfaces,” which include many other wildly varied methods. Some of them include ultrasound imaging equipment, "Non-audible murmur" technology, electromagnetic and radar analysis of vocal tract activity, and even brain implants.
While other Silent Speech Interface methods use ad hoc analytical mathematical models, Silent Voice uses standard data-driven methods, which are much simpler.
I registered Silent Voice in a "Provisional Patent Application" at the USPTO, and they gave me the number "63/637,554" for it.
Here is the end of the free preview of “The Skeptic AI Enthusiast.” Please become a paying subscriber for more exclusive content, including a “Friend Link” to the mentioned article and links for some curated articles on Medium.
Keep reading with a 7-day free trial
Subscribe to The Skeptic AI Enthusiast to keep reading this post and get 7 days of free access to the full post archives.