


OpenAI’s o1: Is It A New Reasoning Paradigm Or Just Smoke And Mirrors?
Perhaps none of them.


Reactions from the pundits to the recently released o1 from OpenAI couldn’t be more contrasting:
“A new paradigm of AI,” writes A. Romero.
“Strawberry is a giant misstep in completely the wrong direction,” writes Will Lockett.
Are we even talking about the same thing? Yes, as you probably know, OpenAI’s o1 became the public name for the “Strawberry” internal project months ago.
But what can we make of such opposite statements? Which one of them is lying? Probably none of them, but one should be utterly wrong, isn’t it?
As often is the case, the truth about OpenAI o1 is way more nuanced than completely opposed opinions. I know, usually, the strongest opinions get the attention spotlight, but my readers know that I prefer to tell things as they are, no BS at all.
What does OpenAI o1 really do?
Some informal statements from Sam Altman, the head of OpenAI, suggested that o1 is a big change because “it can reason.”
Wouldn’t it be a big improvement to incorporate the “reasoning” ability? Of course, it would! Except that, in this case, “reason” is not the right way to put it.
Some analysts have taken the increase in run compute time as a sign that o1 spends time “reasoning.” See, for instance, this graph (by OpenAI):

It shows that “inference time” (the pink area) is now much bigger than before. But since when is taking longer per se a good thing? Is it proof that o1 “reasons”? Further, why do they call “inference” the additional time?
Let me clarify that nobody outside OpenAI knows the ins and outs of o1, so I tried to put together some pieces from the scattered information available.
I concluded that o1 just performs a series of steps it has been trained to do at runtime to get to the right answer.
Let’s piece down this:
A while ago, some ordinary people discovered that adding to the prompt a keyword that implied thinking step by step often improved the outcome.
For instance, I found the advice to precede your prompt with “Ruminate…” Others asked for a “Step-by-step explanation.” Later, Google researchers confirmed this in a research article. Then, OpenAI researchers came up with a systematic approach for doing exactly that, which is the matter of this post.
Chain-of-Thought
Building a step-by-step solution to problems has been called “Chain of Thought” (CoT for short). CoT has been more related to explainability than to accuracy because the steps for arriving at a conclusion can be taken as the explanation instead of having just the final solution.
For instance, if you ask ChatGPT to calculate step by step the largest common divisor of 36 and 16, it will give you something like:
Step 1: Divide 36 by 16
• 36 ÷ 16 = 2 (quotient), with a remainder of:
36 - (16 \times 2) = 36 - 32 = 4
So, 36 ÷ 16 gives a quotient of 2 and a remainder of 4. Now, the next step is to replace the numbers: we now find the GCD of 16 and 4.
Step 2: Divide 16 by 4
• 16 ÷ 4 = 4 (quotient), with a remainder of:
16 - (4 \times 4) = 16 - 16 = 0
Since the remainder is now 0, we stop here. The divisor at this stage (which is 4) is the greatest common divisor of 36 and 16.
Therefore, the largest common divisor of 36 and 16 is 4.
Now, do you call this “to reason”? The bot just followed a well-known sequential algorithm correctly. But following computation steps is what computers have been doing all along, from the beginning of computation. Nothing world-shaking here.
Now add Reinforcement Learning to the mix
For every given query there are many forms of partitioning its solution into individual steps. But how to choose one of them? Enter Reinforcement Learning (RL).
RL isn’t a new technique. I remember when I was a young AI researcher, I went to a scientific conference where most of the presented papers involved RL in some way. RL was all the rage, just as Deep Learning and LLMs are today. After a talk, I was going to ask a question to Dr. Michael Littman–the RL leading scientist at the time–but it was impossible to approach him, as he was surrounded by a huge cloud of adoring graduate students. This gives you an idea of how high was the interest in RL.
But let’s go back to the o1’s working explanation.
Apparently, what o1 does is to start generating candidate step partitions, and then to choose one of them according to which one has the best odds of being successful.
In short, RL works by rewarding and punishing the machine so that it learns optimal behavior.
The RL process would go as follows:
Try one partition candidate and obtain a result R.
Evaluate R so see if it’s any good
If yes, give a “reward,” and if not, give a “punishment.”
Propagate rewards and punishments into the odds of choosing each of the candidates.
Repeat the process.
RL can involve many iterations to make the odds of each option optimal.
One more caveat is that for RL, you need a way of evaluating outcomes to separate the successes from the failures. This is far from trivial.
Summing it up
In brief, OpenAI set up a process to break up prompt solutions into pieces and trained using RL to select which partition to choose. Sure, generating the partitions and then selecting the best one takes time, hence the additional compute time when running.
But a somehow blind process for generating and selecting partitions is hardly called “reasoning.” How do we know how many steps to use? Train the model. And which partitions are better? Train again.
Is this reasoning? Give me a break…
A while ago, I taught the “Automated Reasoning” course at my university, and I covered only symbolic theorem-proving methods. There, the individual steps towards a solution were taken from classical logic, using deduction steps with names like “Modus Tollens,” created by Aristotle a long time ago. That was, I believe, “reasoning.”
Are o1’s results any good?
Perhaps o1 doesn’t “reason,” but this isn’t an obstacle for it to obtain good results. Some figures have been given in the press release by OpenAI:

(Green is GPT-4o, orange is o1).
There are other graphs, but to me, this is the most impressive: in the MATH-500 test, o1 got an almost perfect score of 94.8, compared to the mediocre at best 60.3 of GPT-4o. If this isn’t a good result, I don’t know what would be.
I searched for serious articles evaluating o1 and found one by Arizona State University (ASU) researchers. It’s about planning, which has proven to be one of the most challenging tasks for LLMs.
Without digging too much into the details, just take a look at a comparison of o1 with other LLMS:
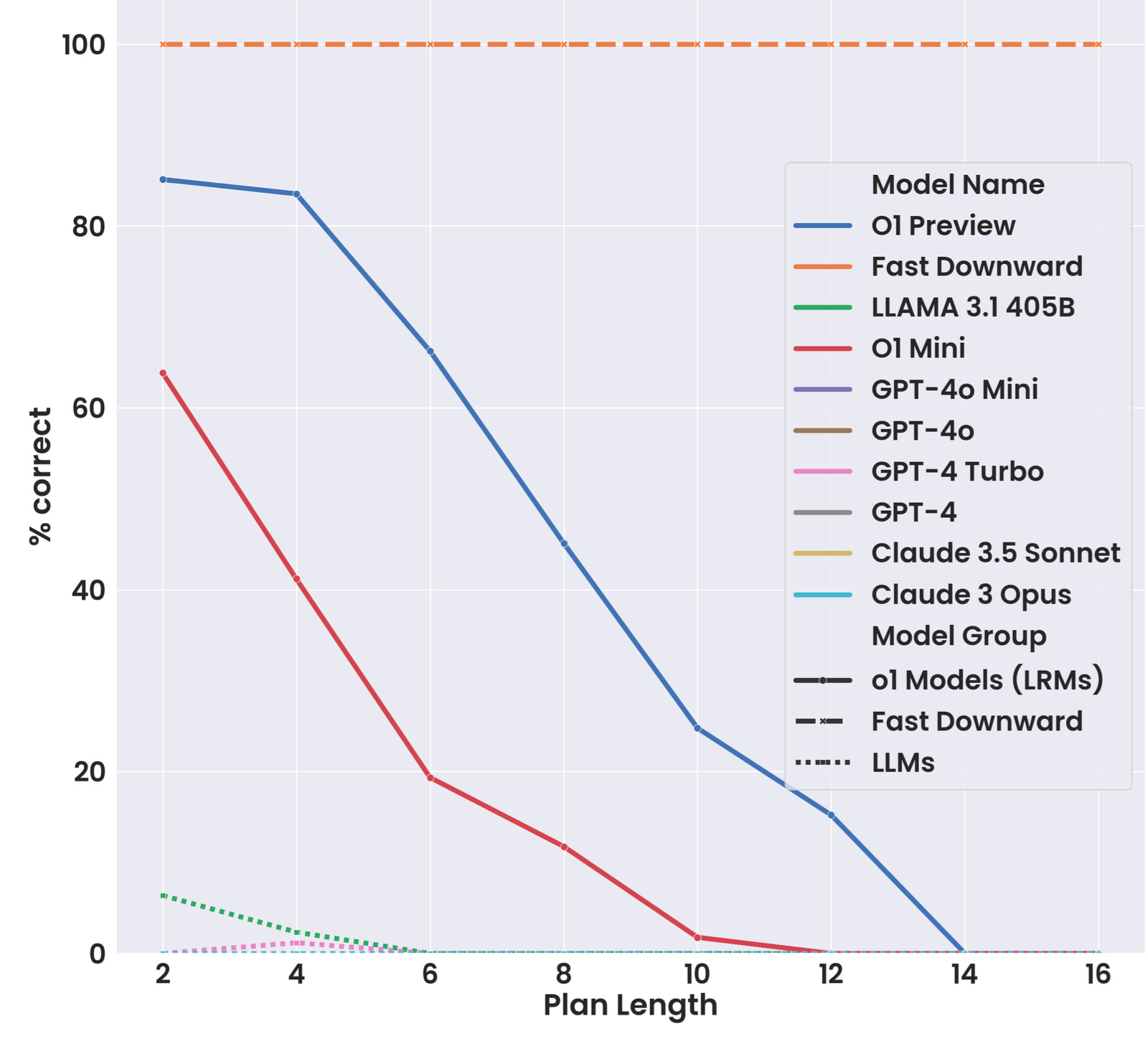
That’s amazing! Every single LLM outside of o1 (preview full model and mini) gives a performance of almost zero, while o1, for plans of length up to 4 steps, has over 80% correct answers.
Take into account that those ASU researchers are leaning towards the AI-skeptic side, to the point that they call “Approximate Retrieval” what regular LLMs do.
My verdict
Keep reading with a 7-day free trial
Subscribe to The Skeptic AI Enthusiast to keep reading this post and get 7 days of free access to the full post archives.